Ohio State nav bar
The Ohio State University
- BuckeyeLink
- Find People
- Search Ohio State

Research Questions & Hypotheses
Generally, in quantitative studies, reviewers expect hypotheses rather than research questions. However, both research questions and hypotheses serve different purposes and can be beneficial when used together.
Research Questions
Clarify the research’s aim (farrugia et al., 2010).
- Research often begins with an interest in a topic, but a deep understanding of the subject is crucial to formulate an appropriate research question.
- Descriptive: “What factors most influence the academic achievement of senior high school students?”
- Comparative: “What is the performance difference between teaching methods A and B?”
- Relationship-based: “What is the relationship between self-efficacy and academic achievement?”
- Increasing knowledge about a subject can be achieved through systematic literature reviews, in-depth interviews with patients (and proxies), focus groups, and consultations with field experts.
- Some funding bodies, like the Canadian Institute for Health Research, recommend conducting a systematic review or a pilot study before seeking grants for full trials.
- The presence of multiple research questions in a study can complicate the design, statistical analysis, and feasibility.
- It’s advisable to focus on a single primary research question for the study.
- The primary question, clearly stated at the end of a grant proposal’s introduction, usually specifies the study population, intervention, and other relevant factors.
- The FINER criteria underscore aspects that can enhance the chances of a successful research project, including specifying the population of interest, aligning with scientific and public interest, clinical relevance, and contribution to the field, while complying with ethical and national research standards.
- The P ICOT approach is crucial in developing the study’s framework and protocol, influencing inclusion and exclusion criteria and identifying patient groups for inclusion.
- Defining the specific population, intervention, comparator, and outcome helps in selecting the right outcome measurement tool.
- The more precise the population definition and stricter the inclusion and exclusion criteria, the more significant the impact on the interpretation, applicability, and generalizability of the research findings.
- A restricted study population enhances internal validity but may limit the study’s external validity and generalizability to clinical practice.
- A broadly defined study population may better reflect clinical practice but could increase bias and reduce internal validity.
- An inadequately formulated research question can negatively impact study design, potentially leading to ineffective outcomes and affecting publication prospects.
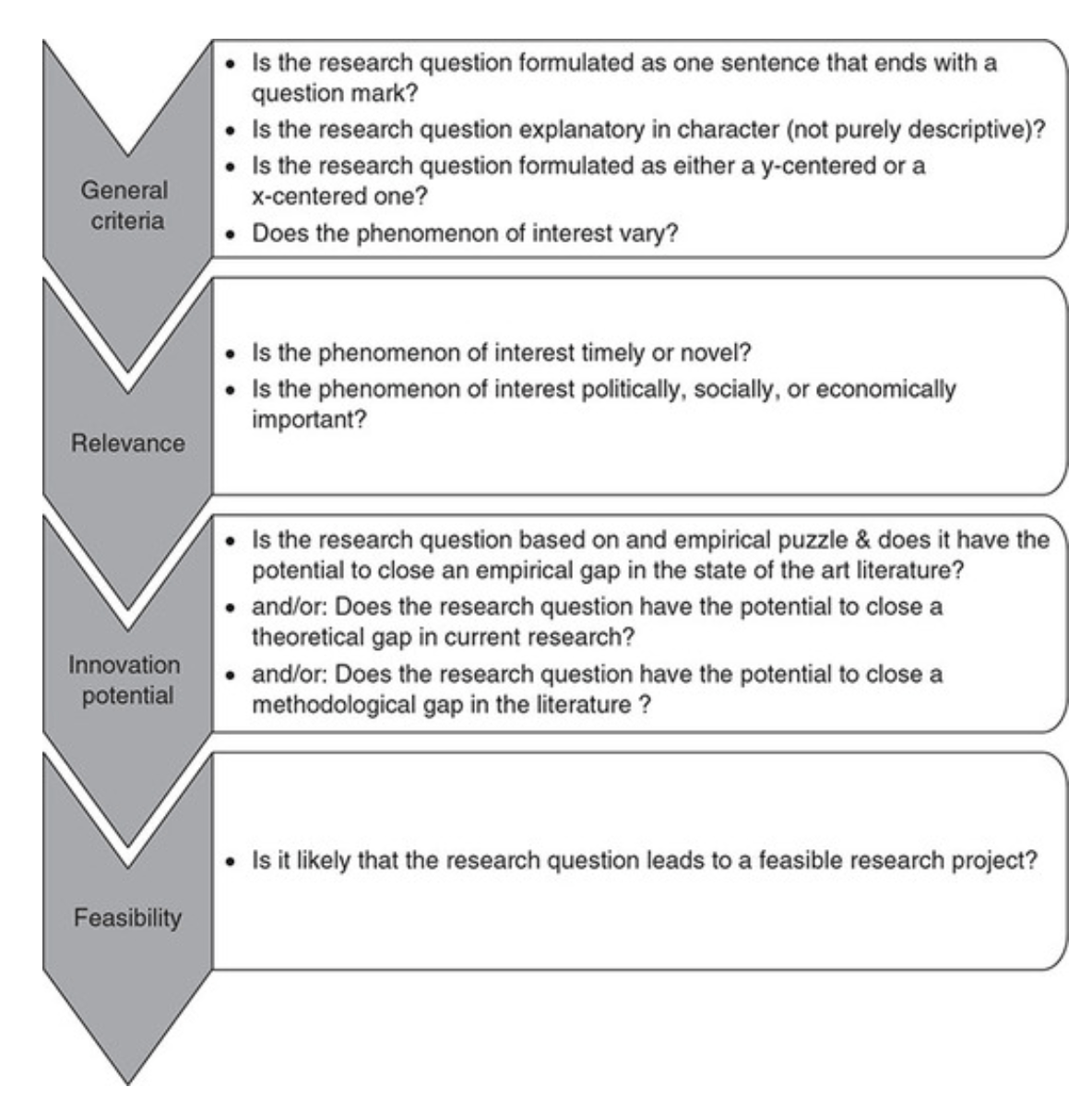
Checklist: Good research questions for social science projects (Panke, 2018)
Research Hypotheses
Present the researcher’s predictions based on specific statements.
- These statements define the research problem or issue and indicate the direction of the researcher’s predictions.
- Formulating the research question and hypothesis from existing data (e.g., a database) can lead to multiple statistical comparisons and potentially spurious findings due to chance.
- The research or clinical hypothesis, derived from the research question, shapes the study’s key elements: sampling strategy, intervention, comparison, and outcome variables.
- Hypotheses can express a single outcome or multiple outcomes.
- After statistical testing, the null hypothesis is either rejected or not rejected based on whether the study’s findings are statistically significant.
- Hypothesis testing helps determine if observed findings are due to true differences and not chance.
- Hypotheses can be 1-sided (specific direction of difference) or 2-sided (presence of a difference without specifying direction).
- 2-sided hypotheses are generally preferred unless there’s a strong justification for a 1-sided hypothesis.
- A solid research hypothesis, informed by a good research question, influences the research design and paves the way for defining clear research objectives.
Types of Research Hypothesis
- In a Y-centered research design, the focus is on the dependent variable (DV) which is specified in the research question. Theories are then used to identify independent variables (IV) and explain their causal relationship with the DV.
- Example: “An increase in teacher-led instructional time (IV) is likely to improve student reading comprehension scores (DV), because extensive guided practice under expert supervision enhances learning retention and skill mastery.”
- Hypothesis Explanation: The dependent variable (student reading comprehension scores) is the focus, and the hypothesis explores how changes in the independent variable (teacher-led instructional time) affect it.
- In X-centered research designs, the independent variable is specified in the research question. Theories are used to determine potential dependent variables and the causal mechanisms at play.
- Example: “Implementing technology-based learning tools (IV) is likely to enhance student engagement in the classroom (DV), because interactive and multimedia content increases student interest and participation.”
- Hypothesis Explanation: The independent variable (technology-based learning tools) is the focus, with the hypothesis exploring its impact on a potential dependent variable (student engagement).
- Probabilistic hypotheses suggest that changes in the independent variable are likely to lead to changes in the dependent variable in a predictable manner, but not with absolute certainty.
- Example: “The more teachers engage in professional development programs (IV), the more their teaching effectiveness (DV) is likely to improve, because continuous training updates pedagogical skills and knowledge.”
- Hypothesis Explanation: This hypothesis implies a probable relationship between the extent of professional development (IV) and teaching effectiveness (DV).
- Deterministic hypotheses state that a specific change in the independent variable will lead to a specific change in the dependent variable, implying a more direct and certain relationship.
- Example: “If the school curriculum changes from traditional lecture-based methods to project-based learning (IV), then student collaboration skills (DV) are expected to improve because project-based learning inherently requires teamwork and peer interaction.”
- Hypothesis Explanation: This hypothesis presumes a direct and definite outcome (improvement in collaboration skills) resulting from a specific change in the teaching method.
- Example : “Students who identify as visual learners will score higher on tests that are presented in a visually rich format compared to tests presented in a text-only format.”
- Explanation : This hypothesis aims to describe the potential difference in test scores between visual learners taking visually rich tests and text-only tests, without implying a direct cause-and-effect relationship.
- Example : “Teaching method A will improve student performance more than method B.”
- Explanation : This hypothesis compares the effectiveness of two different teaching methods, suggesting that one will lead to better student performance than the other. It implies a direct comparison but does not necessarily establish a causal mechanism.
- Example : “Students with higher self-efficacy will show higher levels of academic achievement.”
- Explanation : This hypothesis predicts a relationship between the variable of self-efficacy and academic achievement. Unlike a causal hypothesis, it does not necessarily suggest that one variable causes changes in the other, but rather that they are related in some way.
Tips for developing research questions and hypotheses for research studies
- Perform a systematic literature review (if one has not been done) to increase knowledge and familiarity with the topic and to assist with research development.
- Learn about current trends and technological advances on the topic.
- Seek careful input from experts, mentors, colleagues, and collaborators to refine your research question as this will aid in developing the research question and guide the research study.
- Use the FINER criteria in the development of the research question.
- Ensure that the research question follows PICOT format.
- Develop a research hypothesis from the research question.
- Ensure that the research question and objectives are answerable, feasible, and clinically relevant.
If your research hypotheses are derived from your research questions, particularly when multiple hypotheses address a single question, it’s recommended to use both research questions and hypotheses. However, if this isn’t the case, using hypotheses over research questions is advised. It’s important to note these are general guidelines, not strict rules. If you opt not to use hypotheses, consult with your supervisor for the best approach.
Farrugia, P., Petrisor, B. A., Farrokhyar, F., & Bhandari, M. (2010). Practical tips for surgical research: Research questions, hypotheses and objectives. Canadian journal of surgery. Journal canadien de chirurgie , 53 (4), 278–281.
Hulley, S. B., Cummings, S. R., Browner, W. S., Grady, D., & Newman, T. B. (2007). Designing clinical research. Philadelphia.
Panke, D. (2018). Research design & method selection: Making good choices in the social sciences. Research Design & Method Selection , 1-368.

- Customer Reviews
- Extended Essays
- IB Internal Assessment
- Theory of Knowledge
- Literature Review
- Dissertations
- Essay Writing
- Research Writing
- Assignment Help
- Capstone Projects
- College Application
- Online Class
Research Questions vs Hypothesis: What’s The Difference?

by Antony W
August 1, 2024

You’ll need to come up with a research question or a hypothesis to guide your next research project. But what is a hypothesis in the first place? What is the perfect definition for a research question? And, what’s the difference between the two?
In this guide to research questions vs hypothesis, we’ll look at the definition of each component and the difference between the two.
We’ll also look at when a research question and a hypothesis may be useful and provide you with some tips that you can use to come up with hypothesis and research questions that will suit your research topic .
Let’s get to it.
What’s a Research Question?
We define a research question as the exact question you want to answer on a given topic or research project. Good research questions should be clear and easy to understand, allow for the collection of necessary data, and be specific and relevant to your field of study.
Research questions are part of heuristic research methods, where researchers use personal experiences and observations to understand a research subject. By using such approaches to explore the question, you should be able to provide an analytical justification of why and how you should respond to the question.
While it’s common for researchers to focus on one question at a time, more complex topics may require two or more questions to cover in-depth.
When is a Research Question Useful?
A research question may be useful when and if:
- There isn’t enough previous research on the topic
- You want to report a wider range out of outcome when doing your research project
- You want to conduct a more open ended inquiries
Perhaps the biggest drawback with research questions is that they tend to researchers in a position to “fish expectations” or excessively manipulate their findings.
Again, research questions sometimes tend to be less specific, and the reason is that there often no sufficient previous research on the questions.
What’s a Hypothesis?
A hypothesis is a statement you can approve or disapprove. You develop a hypothesis from a research question by changing the question into a statement.
Primarily applied in deductive research, it involves the use of scientific, mathematical, and sociological findings to agree to or write off an assumption.
Researchers use the null approach for statements they can disapprove. They take a hypothesis and add a “not” to it to make it a working null hypothesis.
A null hypothesis is quite common in scientific methods. In this case, you have to formulate a hypothesis, and then conduct an investigation to disapprove the statement.
If you can disapprove the statement, you develop another hypothesis and then repeat the process until you can’t disapprove the statement.
In other words, if a hypothesis is true, then it must have been repeatedly tested and verified.
The consensus among researchers is that, like research questions, a hypothesis should not only be clear and easy to understand but also have a definite focus, answerable, and relevant to your field of study.
When is a Hypothesis Useful?
A hypothesis may be useful when or if:
- There’s enough previous research on the topic
- You want to test a specific model or a particular theory
- You anticipate a likely outcome in advance
The drawback to hypothesis as a scientific method is that it can hinder flexibility, or possibly blind a researcher not to see unanticipated results.
Research Question vs Hypothesis: Which One Should Come First
Researchers use scientific methods to hone on different theories. So if the purpose of the research project were to analyze a concept, a scientific method would be necessary.
Such a case requires coming up with a research question first, followed by a scientific method.
Since a hypothesis is part of a research method, it will come after the research question.
Research Question vs Hypothesis: What’s the Difference?
The following are the differences between a research question and a hypothesis.
We look at the differences in purpose and structure, writing, as well as conclusion.
Research Questions vs Hypothesis: Some Useful Advice
As much as there are differences between hypothesis and research questions, you have to state either one in the introduction and then repeat the same in the conclusion of your research paper.
Whichever element you opt to use, you should clearly demonstrate that you understand your topic, have achieved the goal of your research project, and not swayed a bit in your research process.
If it helps, start and conclude every chapter of your research project by providing additional information on how you’ve or will address the hypothesis or research question.
You should also include the aims and objectives of coming up with the research question or formulating the hypothesis. Doing so will go a long way to demonstrate that you have a strong focus on the research issue at hand.
Research Questions vs Hypothesis: Conclusion
If you need help with coming up with research questions, formulating a hypothesis, and completing your research paper writing , feel free to talk to us.
About the author
Antony W is a professional writer and coach at Help for Assessment. He spends countless hours every day researching and writing great content filled with expert advice on how to write engaging essays, research papers, and assignments.
Have a thesis expert improve your writing
Check your thesis for plagiarism in 10 minutes, generate your apa citations for free.
- Knowledge Base
- Null and Alternative Hypotheses | Definitions & Examples
Null and Alternative Hypotheses | Definitions & Examples
Published on 5 October 2022 by Shaun Turney . Revised on 6 December 2022.
The null and alternative hypotheses are two competing claims that researchers weigh evidence for and against using a statistical test :
- Null hypothesis (H 0 ): There’s no effect in the population .
- Alternative hypothesis (H A ): There’s an effect in the population.
The effect is usually the effect of the independent variable on the dependent variable .
Table of contents
Answering your research question with hypotheses, what is a null hypothesis, what is an alternative hypothesis, differences between null and alternative hypotheses, how to write null and alternative hypotheses, frequently asked questions about null and alternative hypotheses.
The null and alternative hypotheses offer competing answers to your research question . When the research question asks “Does the independent variable affect the dependent variable?”, the null hypothesis (H 0 ) answers “No, there’s no effect in the population.” On the other hand, the alternative hypothesis (H A ) answers “Yes, there is an effect in the population.”
The null and alternative are always claims about the population. That’s because the goal of hypothesis testing is to make inferences about a population based on a sample . Often, we infer whether there’s an effect in the population by looking at differences between groups or relationships between variables in the sample.
You can use a statistical test to decide whether the evidence favors the null or alternative hypothesis. Each type of statistical test comes with a specific way of phrasing the null and alternative hypothesis. However, the hypotheses can also be phrased in a general way that applies to any test.
The null hypothesis is the claim that there’s no effect in the population.
If the sample provides enough evidence against the claim that there’s no effect in the population ( p ≤ α), then we can reject the null hypothesis . Otherwise, we fail to reject the null hypothesis.
Although “fail to reject” may sound awkward, it’s the only wording that statisticians accept. Be careful not to say you “prove” or “accept” the null hypothesis.
Null hypotheses often include phrases such as “no effect”, “no difference”, or “no relationship”. When written in mathematical terms, they always include an equality (usually =, but sometimes ≥ or ≤).
Examples of null hypotheses
The table below gives examples of research questions and null hypotheses. There’s always more than one way to answer a research question, but these null hypotheses can help you get started.
*Note that some researchers prefer to always write the null hypothesis in terms of “no effect” and “=”. It would be fine to say that daily meditation has no effect on the incidence of depression and p 1 = p 2 .
The alternative hypothesis (H A ) is the other answer to your research question . It claims that there’s an effect in the population.
Often, your alternative hypothesis is the same as your research hypothesis. In other words, it’s the claim that you expect or hope will be true.
The alternative hypothesis is the complement to the null hypothesis. Null and alternative hypotheses are exhaustive, meaning that together they cover every possible outcome. They are also mutually exclusive, meaning that only one can be true at a time.
Alternative hypotheses often include phrases such as “an effect”, “a difference”, or “a relationship”. When alternative hypotheses are written in mathematical terms, they always include an inequality (usually ≠, but sometimes > or <). As with null hypotheses, there are many acceptable ways to phrase an alternative hypothesis.
Examples of alternative hypotheses
The table below gives examples of research questions and alternative hypotheses to help you get started with formulating your own.
Null and alternative hypotheses are similar in some ways:
- They’re both answers to the research question
- They both make claims about the population
- They’re both evaluated by statistical tests.
However, there are important differences between the two types of hypotheses, summarized in the following table.
To help you write your hypotheses, you can use the template sentences below. If you know which statistical test you’re going to use, you can use the test-specific template sentences. Otherwise, you can use the general template sentences.
The only thing you need to know to use these general template sentences are your dependent and independent variables. To write your research question, null hypothesis, and alternative hypothesis, fill in the following sentences with your variables:
Does independent variable affect dependent variable ?
- Null hypothesis (H 0 ): Independent variable does not affect dependent variable .
- Alternative hypothesis (H A ): Independent variable affects dependent variable .
Test-specific
Once you know the statistical test you’ll be using, you can write your hypotheses in a more precise and mathematical way specific to the test you chose. The table below provides template sentences for common statistical tests.
Note: The template sentences above assume that you’re performing one-tailed tests . One-tailed tests are appropriate for most studies.
The null hypothesis is often abbreviated as H 0 . When the null hypothesis is written using mathematical symbols, it always includes an equality symbol (usually =, but sometimes ≥ or ≤).
The alternative hypothesis is often abbreviated as H a or H 1 . When the alternative hypothesis is written using mathematical symbols, it always includes an inequality symbol (usually ≠, but sometimes < or >).
A research hypothesis is your proposed answer to your research question. The research hypothesis usually includes an explanation (‘ x affects y because …’).
A statistical hypothesis, on the other hand, is a mathematical statement about a population parameter. Statistical hypotheses always come in pairs: the null and alternative hypotheses. In a well-designed study , the statistical hypotheses correspond logically to the research hypothesis.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Turney, S. (2022, December 06). Null and Alternative Hypotheses | Definitions & Examples. Scribbr. Retrieved 21 October 2024, from https://www.scribbr.co.uk/stats/null-and-alternative-hypothesis/
Is this article helpful?

Shaun Turney
Other students also liked, levels of measurement: nominal, ordinal, interval, ratio, the standard normal distribution | calculator, examples & uses, types of variables in research | definitions & examples.
Research Hypothesis In Psychology: Types, & Examples
Saul McLeod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul McLeod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
A research hypothesis, in its plural form “hypotheses,” is a specific, testable prediction about the anticipated results of a study, established at its outset. It is a key component of the scientific method .
Hypotheses connect theory to data and guide the research process towards expanding scientific understanding
Some key points about hypotheses:
- A hypothesis expresses an expected pattern or relationship. It connects the variables under investigation.
- It is stated in clear, precise terms before any data collection or analysis occurs. This makes the hypothesis testable.
- A hypothesis must be falsifiable. It should be possible, even if unlikely in practice, to collect data that disconfirms rather than supports the hypothesis.
- Hypotheses guide research. Scientists design studies to explicitly evaluate hypotheses about how nature works.
- For a hypothesis to be valid, it must be testable against empirical evidence. The evidence can then confirm or disprove the testable predictions.
- Hypotheses are informed by background knowledge and observation, but go beyond what is already known to propose an explanation of how or why something occurs.
Predictions typically arise from a thorough knowledge of the research literature, curiosity about real-world problems or implications, and integrating this to advance theory. They build on existing literature while providing new insight.
Types of Research Hypotheses
Alternative hypothesis.
The research hypothesis is often called the alternative or experimental hypothesis in experimental research.
It typically suggests a potential relationship between two key variables: the independent variable, which the researcher manipulates, and the dependent variable, which is measured based on those changes.
The alternative hypothesis states a relationship exists between the two variables being studied (one variable affects the other).
A hypothesis is a testable statement or prediction about the relationship between two or more variables. It is a key component of the scientific method. Some key points about hypotheses:
- Important hypotheses lead to predictions that can be tested empirically. The evidence can then confirm or disprove the testable predictions.
In summary, a hypothesis is a precise, testable statement of what researchers expect to happen in a study and why. Hypotheses connect theory to data and guide the research process towards expanding scientific understanding.
An experimental hypothesis predicts what change(s) will occur in the dependent variable when the independent variable is manipulated.
It states that the results are not due to chance and are significant in supporting the theory being investigated.
The alternative hypothesis can be directional, indicating a specific direction of the effect, or non-directional, suggesting a difference without specifying its nature. It’s what researchers aim to support or demonstrate through their study.
Null Hypothesis
The null hypothesis states no relationship exists between the two variables being studied (one variable does not affect the other). There will be no changes in the dependent variable due to manipulating the independent variable.
It states results are due to chance and are not significant in supporting the idea being investigated.
The null hypothesis, positing no effect or relationship, is a foundational contrast to the research hypothesis in scientific inquiry. It establishes a baseline for statistical testing, promoting objectivity by initiating research from a neutral stance.
Many statistical methods are tailored to test the null hypothesis, determining the likelihood of observed results if no true effect exists.
This dual-hypothesis approach provides clarity, ensuring that research intentions are explicit, and fosters consistency across scientific studies, enhancing the standardization and interpretability of research outcomes.
Nondirectional Hypothesis
A non-directional hypothesis, also known as a two-tailed hypothesis, predicts that there is a difference or relationship between two variables but does not specify the direction of this relationship.
It merely indicates that a change or effect will occur without predicting which group will have higher or lower values.
For example, “There is a difference in performance between Group A and Group B” is a non-directional hypothesis.
Directional Hypothesis
A directional (one-tailed) hypothesis predicts the nature of the effect of the independent variable on the dependent variable. It predicts in which direction the change will take place. (i.e., greater, smaller, less, more)
It specifies whether one variable is greater, lesser, or different from another, rather than just indicating that there’s a difference without specifying its nature.
For example, “Exercise increases weight loss” is a directional hypothesis.

Falsifiability
The Falsification Principle, proposed by Karl Popper , is a way of demarcating science from non-science. It suggests that for a theory or hypothesis to be considered scientific, it must be testable and irrefutable.
Falsifiability emphasizes that scientific claims shouldn’t just be confirmable but should also have the potential to be proven wrong.
It means that there should exist some potential evidence or experiment that could prove the proposition false.
However many confirming instances exist for a theory, it only takes one counter observation to falsify it. For example, the hypothesis that “all swans are white,” can be falsified by observing a black swan.
For Popper, science should attempt to disprove a theory rather than attempt to continually provide evidence to support a research hypothesis.
Can a Hypothesis be Proven?
Hypotheses make probabilistic predictions. They state the expected outcome if a particular relationship exists. However, a study result supporting a hypothesis does not definitively prove it is true.
All studies have limitations. There may be unknown confounding factors or issues that limit the certainty of conclusions. Additional studies may yield different results.
In science, hypotheses can realistically only be supported with some degree of confidence, not proven. The process of science is to incrementally accumulate evidence for and against hypothesized relationships in an ongoing pursuit of better models and explanations that best fit the empirical data. But hypotheses remain open to revision and rejection if that is where the evidence leads.
- Disproving a hypothesis is definitive. Solid disconfirmatory evidence will falsify a hypothesis and require altering or discarding it based on the evidence.
- However, confirming evidence is always open to revision. Other explanations may account for the same results, and additional or contradictory evidence may emerge over time.
We can never 100% prove the alternative hypothesis. Instead, we see if we can disprove, or reject the null hypothesis.
If we reject the null hypothesis, this doesn’t mean that our alternative hypothesis is correct but does support the alternative/experimental hypothesis.
Upon analysis of the results, an alternative hypothesis can be rejected or supported, but it can never be proven to be correct. We must avoid any reference to results proving a theory as this implies 100% certainty, and there is always a chance that evidence may exist which could refute a theory.
How to Write a Hypothesis
- Identify variables . The researcher manipulates the independent variable and the dependent variable is the measured outcome.
- Operationalized the variables being investigated . Operationalization of a hypothesis refers to the process of making the variables physically measurable or testable, e.g. if you are about to study aggression, you might count the number of punches given by participants.
- Decide on a direction for your prediction . If there is evidence in the literature to support a specific effect of the independent variable on the dependent variable, write a directional (one-tailed) hypothesis. If there are limited or ambiguous findings in the literature regarding the effect of the independent variable on the dependent variable, write a non-directional (two-tailed) hypothesis.
- Make it Testable : Ensure your hypothesis can be tested through experimentation or observation. It should be possible to prove it false (principle of falsifiability).
- Clear & concise language . A strong hypothesis is concise (typically one to two sentences long), and formulated using clear and straightforward language, ensuring it’s easily understood and testable.
Consider a hypothesis many teachers might subscribe to: students work better on Monday morning than on Friday afternoon (IV=Day, DV= Standard of work).
Now, if we decide to study this by giving the same group of students a lesson on a Monday morning and a Friday afternoon and then measuring their immediate recall of the material covered in each session, we would end up with the following:
- The alternative hypothesis states that students will recall significantly more information on a Monday morning than on a Friday afternoon.
- The null hypothesis states that there will be no significant difference in the amount recalled on a Monday morning compared to a Friday afternoon. Any difference will be due to chance or confounding factors.
More Examples
- Memory : Participants exposed to classical music during study sessions will recall more items from a list than those who studied in silence.
- Social Psychology : Individuals who frequently engage in social media use will report higher levels of perceived social isolation compared to those who use it infrequently.
- Developmental Psychology : Children who engage in regular imaginative play have better problem-solving skills than those who don’t.
- Clinical Psychology : Cognitive-behavioral therapy will be more effective in reducing symptoms of anxiety over a 6-month period compared to traditional talk therapy.
- Cognitive Psychology : Individuals who multitask between various electronic devices will have shorter attention spans on focused tasks than those who single-task.
- Health Psychology : Patients who practice mindfulness meditation will experience lower levels of chronic pain compared to those who don’t meditate.
- Organizational Psychology : Employees in open-plan offices will report higher levels of stress than those in private offices.
- Behavioral Psychology : Rats rewarded with food after pressing a lever will press it more frequently than rats who receive no reward.
- Privacy Policy
Home » Research Hypothesis Vs Null Hypothesis
Research Hypothesis Vs Null Hypothesis
Table of Contents

The difference between Research Hypothesis Vs Null Hypothesis is as follows:
Research Hypothesis
A Research Hypothesis is a tentative statement that proposes a relationship between two or more variables. It is based on a theoretical or conceptual framework and is typically tested through empirical research.
Null Hypothesis
A Null Hypothesis is a statement that proposes that there is no relationship between two or more variables. It is the opposite of the research hypothesis and is used as a comparison in statistical analysis.
Comparison Table:
In summary, a research hypothesis proposes a relationship between variables, while a null hypothesis proposes no relationship between variables. The research hypothesis guides empirical research, while the null hypothesis is used as a comparison in statistical analysis. The research hypothesis is supported if statistical analysis provides evidence to reject the null hypothesis, while the null hypothesis is rejected if statistical analysis provides evidence to support the research hypothesis.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Generative Vs Evaluative Research

Market Research Vs Marketing Research

Correlational Research Vs Experimental Research

Research Question Vs Hypothesis

Basic Vs Applied Research

Exploratory Vs Explanatory Research
IMAGES
VIDEO
COMMENTS
The null and alternative hypotheses are two competing claims that researchers weigh evidence for and against using a statistical test: Null hypothesis (H0): There’s no effect in the population. Alternative hypothesis (Ha or H1): There’s an effect in the population.
After statistical testing, the null hypothesis is either rejected or not rejected based on whether the study’s findings are statistically significant. Hypothesis testing helps determine if observed findings are due to true differences and not chance.
A research hypothesis is a mathematical way of stating a research question. A research hypothesis names the groups (we'll start with a sample and a population), what was measured, and which we think will have a higher mean. The last one gives the research hypothesis a direction.
You develop a hypothesis from a research question by changing the question into a statement. Primarily applied in deductive research, it involves the use of scientific, mathematical, and sociological findings to agree to or write off an assumption. Researchers use the null approach for statements they can disapprove.
In a qualitative study, inquirers state research questions, not objectives (i.e., specific goals for the research) or hypotheses (i.e., predictions that involve variables and statistical tests). These research questions assume two forms: a central question and associated subquestions.
When the research question asks “Does the independent variable affect the dependent variable?”, the null hypothesis (H 0) answers “No, there’s no effect in the population.” On the other hand, the alternative hypothesis (H A ) answers “Yes, there is an effect in the population.”
Null hypotheses (H0) start as research questions that the investigator rephrases as statements indicating no effect or relationship between the independent and dependent variables. It is a default position that your research aims to challenge or confirm.
The null hypothesis in statistics states that there is no difference between groups or no relationship between variables. It is one of two mutually exclusive hypotheses about a population in a hypothesis test.
Types. Falsifiability. Can a Hypothesis be Proven? How to Write a Hypothesis. Examples. A research hypothesis, in its plural form “hypotheses,” is a specific, testable prediction about the anticipated results of a study, established at its outset. It is a key component of the scientific method.
In summary, a research hypothesis proposes a relationship between variables, while a null hypothesis proposes no relationship between variables. The research hypothesis guides empirical research, while the null hypothesis is used as a comparison in statistical analysis.